Synchronize nested Azure AD Groups with Databricks User Groups — A Guide to Effortless User Management!
Are you tired of managing user groups on multiple platforms and keeping track of updates in each one of them? Well, it’s time to automate the process and streamline your work with Azure Active Directory (AD) and Databricks. In this guide, we’ll show you how to sync selected Azure AD groups with Databricks user groups and make user management easier!
Overview of the automation:
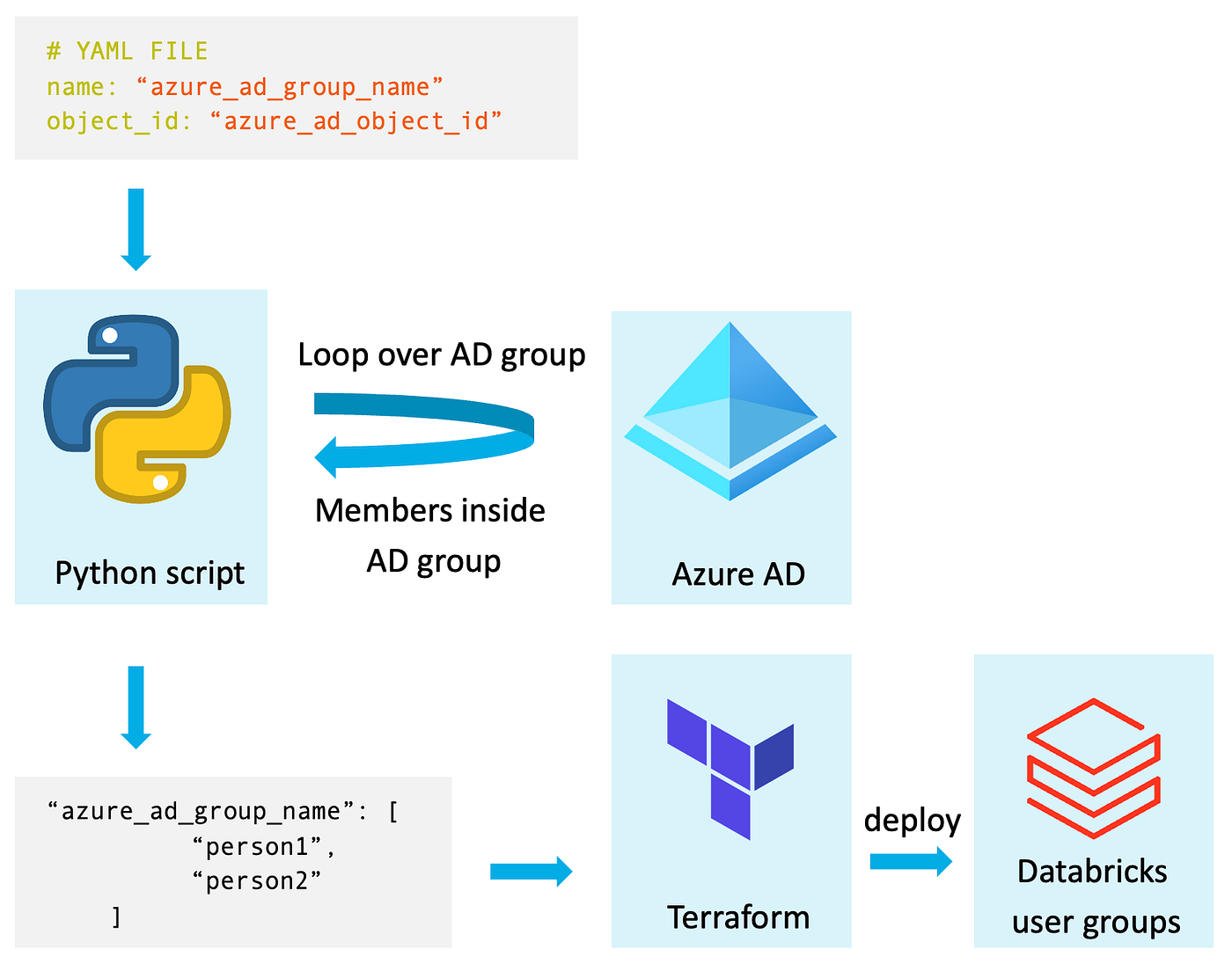
Step 1: Collect Azure AD Group Information.
The first step is gathering information about the Azure AD groups you want to sync with Databricks. This can be done by using a script that takes in a YAML file containing the Object ID of an Azure AD group. The script then loops over all the members inside the group, including nested AD groups.
The YAML file (user_groups/azure_ad_group.yaml):
object_id: "<azure_ad_object_id>"
The python script:
import json
import requests
import adal
import os
import logging
from pathlib import Path
logging.basicConfig(level=logging.INFO)
tenant_id = "<azure tenant id>"
client_id = "<deployment spn client id>"
client_secret = "<deployment spn client secret>"
context = adal.AuthenticationContext(
f'https://login.microsoftonline.com/{tenant_id}')
token = context.acquire_token_with_client_credentials(
'https://graph.microsoft.com',
client_id,
client_secret
)
graph_api_url = 'https://graph.microsoft.com/v1.0'
headers = {'Authorization': f'Bearer {token["accessToken"]}'}
groups = []
base_path = Path("user_groups")
configs = base_path.glob("*/*.yaml")
for config in configs:
config = yaml.safe_load(open(config).read())
groups.extend(config)
# Recursively fetch members of all groups
logging.info('Found %d groups', len(groups))
def fetch_members(group_id):
members = []
group_url = f'{graph_api_url}/groups/{group_id}/members'
response = requests.get(group_url, headers=headers)
if response.status_code == 200:
group_members = json.loads(response.text)['value']
for member in group_members:
if member['@odata.type'] == '#microsoft.graph.user':
members.append(member)
elif member['@odata.type'] == '#microsoft.graph.group':
members.extend(fetch_members(member['id']))
else:
print(response.text)
# make sure the dict is distinct, as nested groups might contain a member again
distinct_members = list(
{v['userPrincipalName']: v for v in members}.values())
return distinct_members
for group in groups:
members = fetch_members(group['object_id'])
logging.info('Found %d members for group %s',
len(members), group['name'])
os.mkdir('groups') if not os.path.exists('groups') else None
group_object = {'name': group['name'], 'members': [
member.get('userPrincipalName') for member in members]}
with open(f'groups/{group["name"]}.yaml', 'w') as fp:
yaml.dump(group_object, fp)
Step 2: Deploy the Azure AD Group to Databricks
Once you have the list of members for each Azure AD group, the next step is to deploy it to Databricks as a user group. This can be done using Terraform, which is a popular infrastructure-as-code tool. With Terraform, you can deploy the Azure AD group to a Databricks user group with the same members. Important: You need to have admin privileges on the Databricks accounts console and then you also need to use this as your Terraform provider (https://docs.databricks.com/administration-guide/account-settings-e2/index.html)
The Terraform module:
display_name = var.group_name
}
data "databricks_user" "user" {
user_name = each.value
for_each = toset(var.members)
}
resource "databricks_group_member" "group_member" {
group_id = databricks_group.user_group.id
member_id = data.databricks_user.user[each.value].id
for_each = toset(var.members)
depends_on = [
databricks_group.user_group
]
}
Calling the module:
source = "../modules/user_groups"
group_name = each.value.name
members = each.value.members
for_each = var.user_groups
providers = {
databricks = databricks.accounts_console
}
}
Step 3: Monitor the Synchronization
Finally, it’s important to regularly monitor the synchronization process to ensure that the Databricks user groups match the Azure AD groups. This can be done by scheduling a Github (or any other) CI job that runs the code. The advantage of using Terraform is that it only deploys changes when a group member is added, removed, or changed, reducing the risk of errors and reducing deployment time.
Conclusion
In conclusion, syncing selected Azure AD groups with Databricks user groups is a fantastic way to centralize your user group information and simplify the management process. With the help of the python script and Terraform, you can automate the process and ensure that your groups stay up-to-date easily. Give it a try and make user management easier!

